I’ve always thought the US Postal Service is such a technological marvel. They somehow manage to identify and route billions of pieces of mail and I have to imagine their tech is significantly more primitive than this. Not only that but US addresses are absurdly non-standardized, you can often write the same address multiple ways and have it deliver to the same location. I’m sure there’s plenty of published knowledge in this area, but whenever I see announcements about OCR it feels like this should be a solved problem if it’s been accomplished at the scale of USPS for many years.
My father once received a letter from Algeria, with 3 words on the envelope : his first name, "Créteil" (the town where he lived, ≈100k inhabitants), and "France". Of course, in the 70s there was no Internet nor central database to find him, yet the postal service managed to deliver the letter. He was a very active social worker, managed a youth football team, etc. which made him locally well-known by his first name.
Nowadays, many people can't find anyone or any place unless their phone helps them. And postmen never stop to chat. Such a letter would not pass through the technology process, and probably not through the human network.
I used to part time for the (Danish) mail service.
The only sorting that was done automatically was the post codes. That was enough to get the letter to the right post office. The rest was done by the mailmen/women early in the morning.
It was a lot of fun trying to figure out what was meant by some of the addresses. The older people in particular often knew the story of why certain places were sometimes addressed in certain ways, or could guess the addresses based on the names of the people living there.
The USPS Remote Encoding Center in Salt Lake City examined 841,260,847 images of poorly written addresses in fiscal year 2025. [0]
Unfortunately the page does not have a base rate--the total number of mail pieces that were not prepared for automated processing. Total first class mail, which includes a lot of bills prepared for automation was 25.7 billion [1]. If 10% of that are non-automated, then .8 / 2.57 = .31 or a third of mail not prepared for automation is handled by "employees look at the image and type in address information"
I can't help you with any of those questions... but back in the 90s I use to be one of those employees that looked at the image on the screen and typed the address information in Salt Lake City.
Quantitatively, I don't know the stats, but qualitatively I can confirm it felt like a lot.
I’m not totally sure what your point is, but my response is that most OCR technology is reading “automated” (i.e. computer-printed) documents such as PDFs and things like that. So I think parsing the numbers by “automated” vs “non-automated” is not a very helpful way to think about the success of USPS OCR technology; the gross percentage of manual reviews compared to total mail volume is a much better way at looking at the success of their OCR. That’s my perspective anyway, but maybe commercial OCR is really optimized for reading handwriting and I’m just not aware of it. I’m not an expert in the area.
A tangential observation: the video on the linked page wasn't what I expected. I thought Mistral was a european AI company, so I didnt expect the video to be filmed in San Francisco featuring three people who don't seem to be european.
I'm not against them being a global organization, that's wonderful. I was just surprised. I expected a parisian office and european accents.
Unfortunately Europeans are terrible customers for making money. They ask a lot of questions and they're very stingy with their wallets. Americans on the other hand ...
This is absolutely not why there are no leading AI, other important silicon tech, or relevant space companies in Europe. To some degree they exist but are all B-Tier in comparison to US/China. You'd be surprised just how lose money can sit in Europe, I guess. Just not the way it needs to be for this.
The financial structure of the EU is nowhere close to enabling these capital devouring endeavors based on lofty future bets. Operating at a loss for years and years is simply unacceptable in European markets and the EU is not authoritarian enough to randomly divert capital based on political orders like China because the EU doesn't try to be a superpower controlling a hemisphere.
>You'd be surprised just how lose money can sit in Europe, I guess
Can you share which are those industries with lose money?
>EU is not authoritarian enough to randomly divert capital based on political orders like China
Except it seems it was authoritarian enough to manage to divert taxpayer funds for refugees, covid, Ukraine, etc in an instant when the shit hit the fan. But somehow for risky industries vital to domestic sovereignty, that's not possible.
I guess because there's not a well developed kickback industry yet in place for the latter as it is for the former, so politicians handing out the cash to their industry friends can't grift so easily, like they did in Covid for example, or at least not yet.
~Any borderline-large European tech company will have an office on the US west coast, for sales if nothing else. And probably sales engineering. The timezone difference is eight to ten hours; there is really no way around it.
(I did work for one which had an office in Vancouver, instead; same tz.)
Another company like this is Blackmagic Design. Despite being overwhelmingly based in Australia, you'd think it was an American company based on office listing ordering on https://www.blackmagicdesign.com/company/offices and /company page.
To the best of my knowledge, most of the founding team started their careers in the US ( meta,etc..) and their primary investors are US VCs. In that regard, they smartly benefit on both side : US funding and European brains
It's cheap at $4/1k, but I'm hesitant to even benchmark this one again since the previous versions were all "98% accurate based on internal benchmarks of 4 pdfs" and ended up falling short of almost everything else on the market [1].
Even in this one, they just report that OlmOCRBench and OmniDocBench have "known limitations" and that's why they report flagship numbers from their internal benchmark.
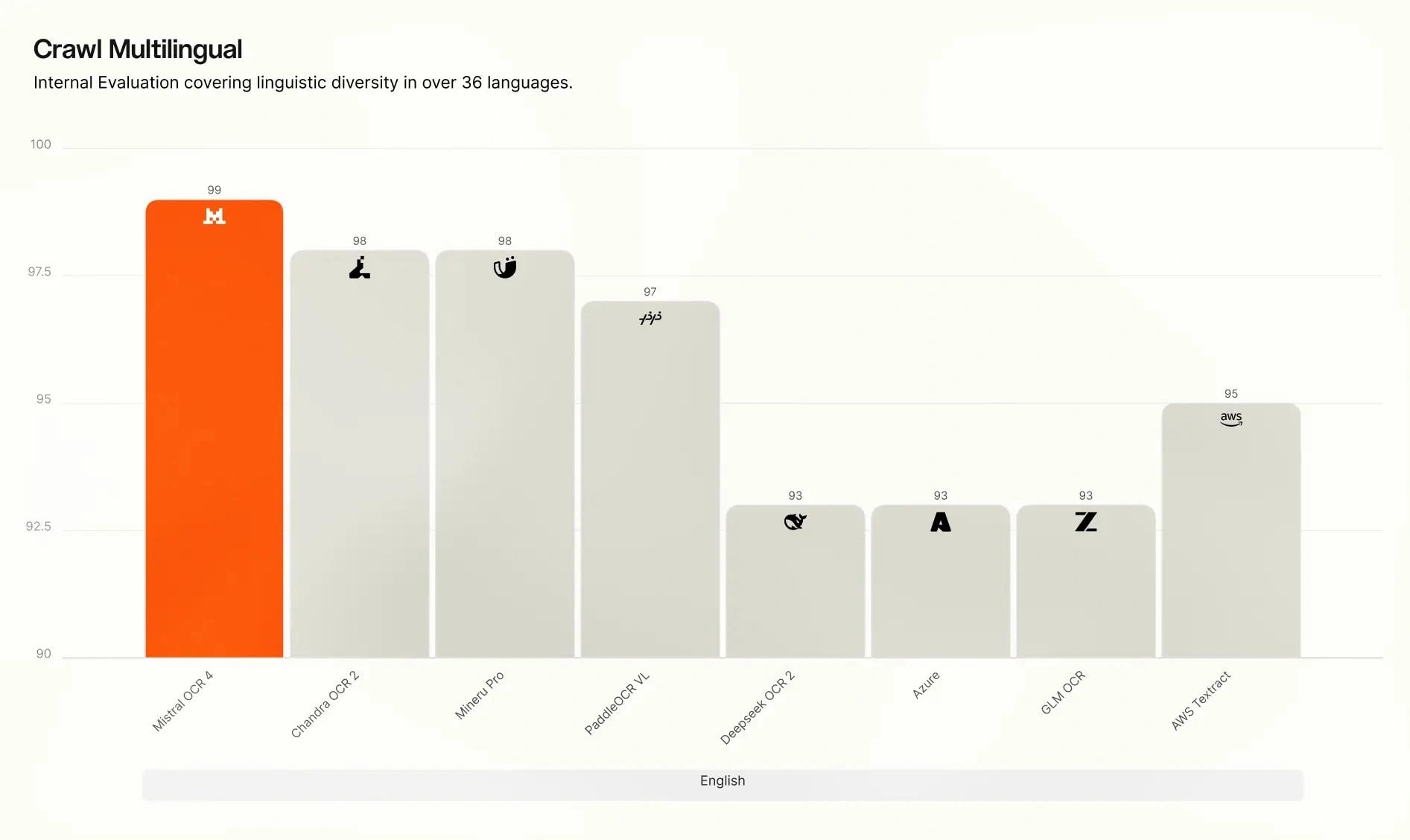
> On our internal multilingual evaluation, OCR 4 leads across all eight language groups — English, Western Europe, Eastern Europe, Middle Eastern, Chinese, East Asian, Southeast Asian, and specialized languages (Hindi, Japanese, Georgian, Bengali, Armenian, Hebrew, Greek, Gujarati, Tamil, Malayalam, Kannada, Telugu).
The initial version of this page called these "minor languages" (vs specialized language), which is telling. If you're a speaker of one of these: This is why you need a sovereign set of models. (Japanese government: Are you listening?)
Tested with Malayalam, normal handwriting got accurate but a slight different style got detected as kannada. Have samples if required, which sarvam got done with 99% accuracy leaving one text error.
I'm curious what's been your experience with Sarvam outside of Indic languages - Indian English (perhaps mixed with romanised indic verbiage) and also documents with complex layouts (figures, tables, etc).
I've been quite curious but hesitant about Indian offerings, particularly because they seem to be priced a little higher than what I would think they should be (I could be wrong and simply be misrembering though).
Sarvam is exceptionally tuned for indic languages we have more than 20 languages and it perform well for all in ocr. Iam yet to test with other languages. No any models come close for indic languages like sarvam. I saw they recently dropped price per page to 0.5 inr which is much cheaper. The only downside is the zip file based delivery.
Little on differences other than bounding boxes and double the price compared to their previous OCR v3 model from December - https://mistral.ai/news/mistral-ocr-3/ - other benchmarks were used back then.
"A note on out-of-scope use. OCR 4 is a document-understanding model, not a decision-maker. It is not intended for medical diagnosis, legal advice or judgment, high-stakes financial decisions, safety-critical systems, real-time/latency-sensitive processing, or non-document inputs (raw audio, video, etc.). "
Can't wait for the "oh so innovative" manager who will suggest during the next meeting "Ok... but what if WE used it for high-stakes financial decisions on non-document inputs like a photo from my phone?"
I guarantee you somebody on HN is going to comment about this "idea" next week.
Why would anybody do that you would simply get terrible results compared to dozens of other more capable models. It's for converting to text not answering questions. Just seems like you need some sort of weird angle to bring out an anti AI stance
All AI companies are working on models with specialisms. Which are really good at one task.
Mistral is just a bit more forward about this. I guess because they don't need/want to "wow" an audience with generalist user-facing tools (chat) that seem to be experts in everything (but in reality quite often will be a lot of such specialist models chained together).
Here, what you want, is really just a few python scripts away. Voxtral to turn your spoken prompt into text, piped into mistral large 3 with extra system prompts that creates a prompt for ocr and paths to files. It could do this in a loop to actually find those files. which you throw at ocr3, is pased back to misteal large 3 to interpret and turn into decisions.
This is common. It's rather uncommon, really, to build something like this using only one model for everything.
Recently I tied OCR with Opus 4.8. (I know, not technically right tool for the job). All I needed to do was extract dates from receipts. It got about 20% of the dates wrong yet rated all as “high confidence”.
Should have probably tried a more OCR specific model
> All I needed to do was extract dates from receipts
Was this... not basically a solved problem like 30 years ago? I'm pretty sure the shareware OCR tool that came with a black and white scanner I had at one point would do better than 20% wrong.
I don't know about Opus but I can tell you with Gemini the subscription product OCR is apparently not done by the model. It used a separate old fashioned OCR tool and gives bad results in my tests.
But with Gemini the API the model does do the OCR resulting in much better accuracy.
How long have you been testing this? Have you noted a large improvement? I tested Opus for this quite a while ago (maybe 4.5? Whatever was out about a year ago), and it performed quite poorly on my use case.
I have put together an internal benchmark on 1000s of business documents with weird tables, structure, etc. that I run on every relevant model release. Opus 4.8 performs very very well. But it is obviously overkill for the task (and expensive at doing so). I just wanted to respond to the OP.
I'm assuming that the reason I didn't have good success rate is because it was not scanned documents, but photographs, and lighting conditions weren't always ideal. I think scanned business documents are a happy-case scenario in a way. (obv, you seem to run it against some complex documents, so that's impressive)
Opus 4.8 scanned hundreds of PDFs for me recently with the worst handwriting imaginable. 100% successful, other than one record where even I could not figure out what was written.
I do not believe this story, because of the message I just posted above.
That's not really productive lol, I'm glad it worked for you but these models are non-deterministic and 'YMMV' very much applies everywhere. I had it parse receipts (in fairness, in variable lightning), all taken from iPhone cameras in the past year. And yeah, not a great job, about 20% failed to get the date correct. (Not outrageously wrong, e.g 05/20/2026 becomes 05/23/2026.
I think until Fable, Claude's vision was significantly worse than GPT and Gemini in my personal experience. I eval almost every vision model since I work on screenshot to code conversion project: https://github.com/abi/screenshot-to-code.
I was processing 55 year old paper files, most of them severely degraded, with its predecessor model. I was very impressed! I also tried Abbyy Finereader but it didn't even come close in my experience.
I used Abbyy Finereader for several years. I loved it. I completed some large projects with it. Modern VLMs put classic FineReader to shame for processing low-resolution/degraded/non-standard text.
I'm personally using the small Qwen 3.5 models. If you have an OCR problem, Mistral OCR 4 is probably great. Open weights models that you can run on a laptop may also work great.
Given this a test on some scans of magazines, generally pretty impressed with the results. Mags are generally pretty whacky layouts and it does a reasonable job working out what is where and pulling it together into a single coherent md file. The way it crops relevant pics and puts them into the doc is pretty nice.
Haven't compared it with any other high tech OCR estups, but it's way better than the jank that comes as standard with my scanner.
Does anyone know of OCR benchmarks that include hand-written documents? I'm currently using Gemini pro 3 for this, and error rates are quite good, but it's a little bit pricey, and I'd be interested in a cheaper model that could perform as well, but almost all the OCR benchmarks I'm aware of (and I believe all the ones included in this announcement) are about printed/typeset text.
It’s not the same service. Google’s vision OCR is pure text extraction, not layout. Pretty sure Google’s doc AI services that can identify headers vs body text is $10 per 1k pages.
That’s true, though worth beating a dead horse to say that traditional OCR won’t hallucinate sentences, perform unwanted translation, or change the meaning of whole paragraphs to something more “appropriate”.
Not well tested. It switched all U.S. (") double quotation marks to UK-style (') single quotation marks, ignoring the source document. Useless in the US.
Are there benchmarks for how this performs on charts, or maybe more accurately, plots? I've yet to find a model that can digitize a plot into X,Y points with some accuracy in my use case of digitizing old datasheets.
I was just using infinity parser 2 (flash, to be fair) for pennies self-hosted to run through thousands of pages of documents with remarkable confidence. I decided to use https://huggingface.co/datasets/allenai/olmOCR-bench to determine what was the best OCR tool, yesterday, but I've got no idea what the best is now. What is the dominant OCR eval right now? Between Baidu and Mistral this morning, I wonder if there's a new tool to switch to..
Yes, we've been using Transkribus for this extensively. My wife is a historian who spends quite a bit of time sorting through old letters and diaries, and it has been a considerable quality of life improvement.
Even if you are able to read someone's scratches, having a model to do the bulk lifting saves your eyes a lot of squinting. One thing that makes Transkribus useful for research vs a chat interface is that it can line up its interpretation alongside the original image so you can examine its work directly.
In the sense that you can get similarity scores for individual characters referenced against a known database of characters written by various individuals. You can get stylometry scores out of small LLMs that do demographic segmentation based on writing style using the same methods.
They won't have the capacity to be fed an image of handwritten text and say "Ahh, this is a note written by Winston Churchill!". You could very easily use these models and your agent framework of choice, like Hermes, the Segment Anything models, and other foss tooling to build a dedicated, specialist handwriting recognition system. Or facial recognition, or fingerprint recognition, etc - these sorts of things can be done very procedurally, without a lot of interpretive AI.
Yes, we have successfully used Mistral OCR for digitizing handwritten forms. You always have low percentage that need human review and adjustment, but overall Mistral has been highly accurate (their price is amazing, too).
Edit: I also asked Gemini 3.1 Pro to analyze the certificate and it looks good
It looks like you have shared an `about:certificate` URL containing a chain of three Base64-encoded X.509 TLS/SSL certificates. This specific chain is used to secure connections to *mistral.ai*.
Here is the decoded breakdown of the certificate chain you provided:
## Certificate Chain Overview
This is a standard three-tier certificate chain issued by Google Trust Services for the Mistral AI domain.
---
### 1. Leaf Certificate (End-Entity)
This is the specific certificate issued to the website to verify its identity and encrypt traffic.
After paying for Mistral and using it for a while I genuinely hated it. It's a productivity black hole and can't realistically compete with anyone. I chose it only because it was European, but no. I'd rather let my one year subscription go to waste than use anything 'Mistral'.
Sure, well for me it isn't. It has been awful for even toy tasks that opencode's free plan did without an issue. The general sentiment about it is that it is really bad. I wish I knew before paying.
The armies of people desperate to defend mistral, scouring the internet for any of the hundreds of negative posts made about it daily is pathetic. There's a reason it needs 'fanboys' and 'defenders'... it sucks. Id have loved to use a European alternative, but Europeans need to get serious and actually offer an alternative that has value other than "it's trash, but it has a Made in Europe badge".
{kind=link}
reply